
Introdução ao RUFUS Blueprint
Bem-vindo ao RUFUS Blueprint…
Este artigo é uma tradução do artigo original feito pelo site Seller Sessions, e analisa os fundamentos do Rufus, destacando suas inovações protegidas por patentes, capacidades e as estratégias de otimização de SEO e produtos que os vendedores podem usar para prosperar na nova era.
Ao longo dos próximos 3 posts, detalhamos como o Rufus está influenciando a arte e a ciência das compras online. Também incluímos um “Prompt-A-Long”, onde você pode fazer perguntas ao bot na barra lateral enquanto lê, para obter mais insights, além de um glossário de termos para ajudar a entender melhor algumas expressões novas.
Prepare-se, pegue um café e mergulhe conosco. Vamos começar…
Resumo: RUFUS da Amazon
Principais características do RUFUS
- Compreensão Semântica: Foco no contexto e nos significados, utilizando frases nominais para vincular a intenção do comprador aos produtos.
- Otimização de Inferências: Conecta características dos produtos aos benefícios, atendendo às necessidades dos compradores, mesmo que não sejam declaradas diretamente.
- Aprendizado em Tempo Real: Refina as recomendações com base nas interações dos usuários e em perguntas geradas pelo sistema.
- Classificação de Recomendações: Prioriza por relevância semântica, cliques dos usuários e dados de treinamento.
- Adaptabilidade Dinâmica: Personaliza recomendações com base no caminho e na intenção do comprador.
- Rotulagem Visual com Etiquetas (VLT): Melhora as imagens com sobreposições descritivas e texto alternativo para facilitar a descoberta.
Otimização para RUFUS
- Integre Texto às Imagens: Alinhe rótulos descritivos com características principais dos produtos.
- Otimização de Frases Nominais (NPO): Use frases nominais detalhadas e incorpore características, materiais e benefícios.
- Aprimoramento de Q&A: Forneça respostas naturais e conversacionais para perguntas frequentes.
- Construção de Conteúdo Semântico: Foque em contextos relevantes e cenários de uso.
- Otimização de Inferências (IO): Mapeie os atributos dos produtos para benefícios inferidos.
Descobrindo o RUFUS através de sua patente
Ao desenvolver o Rufus, a Amazon precisava garantir que ele não fosse apenas uma ferramenta para responder perguntas dos compradores. O Rufus precisava ir além — ele deveria analisar essas perguntas e as respostas fornecidas, identificar frases-chave e usar essas informações para recomendar produtos relevantes. Além disso, ele precisava classificar essas recomendações de forma eficaz, melhorando a experiência de compra e aumentando a visibilidade dos produtos.
Essa aplicação de patente explora os mecanismos por trás desse processo. Ela descreve como o Rufus identifica insights valiosos a partir das interações dos clientes na seção de Perguntas e Respostas (QA) e os transforma em recomendações acionáveis.
Entendendo o Rufus: Além da Correspondência de Palavras-Chave
Por exemplo, se você perguntar:
“Como remover unhas de gel?”
O RUFUS não se limitará a responder:
“A remoção de unhas de gel envolve mergulhá-las em acetona pura.”
Ele também conectará os pontos, identificando “acetona pura” como uma informação-chave e sugerindo produtos, como removedores de acetona, que atendem à sua consulta. [Fig. 1]

O que torna o Rufus tão inteligente é sua capacidade de ir além da simples correspondência de palavras-chave. Ele utiliza Processamento de Linguagem Natural (NLP) avançado para analisar e compreender profundamente tanto as perguntas dos compradores quanto as respostas fornecidas.
Central a isso está o conceito de n-grams, que são sequências de palavras ou frases analisadas em conjunto para capturar o contexto. Por exemplo, em vez de tratar “unhas de gel” e “acetona pura” como termos desconectados, o Rufus analisa essas frases como unidades significativas — o que os especialistas em NLP frequentemente chamam de frases nominais.
Ao identificar frases nominais em perguntas e respostas, o Rufus destaca ideias-chave que mais importam para o usuário. Quando um comprador pergunta sobre “remoção de unhas de gel”, ele reconhece que “acetona pura” é uma parte essencial da solução, mesmo que essas palavras não apareçam diretamente na pergunta. Essa abordagem permite que o Rufus vá além da correspondência simples de palavras, desbloqueando conexões entre conceitos que tornam suas recomendações muito mais relevantes.
O Rufus não para no entendimento da linguagem — ele aprende com o comportamento. Cada clique em uma recomendação fornece feedback ao sistema. Com o tempo, esses dados refinam sua capacidade de prever quais produtos serão mais atrativos para futuros compradores. O processo melhora continuamente à medida que o Rufus se torna melhor em reconhecer quais frases e atributos dos produtos são mais importantes com base nas ações dos usuários.
Aprimorando a Descoberta de Produtos por Meio da Compreensão Semântica
Aproveitando essas técnicas, o Rufus conecta de forma fluida perguntas, respostas e produtos. Ele não apenas lista itens com palavras-chave correspondentes — ele identifica os produtos certos ao entender o contexto completo de uma consulta.
No Rufus da Amazon, o entendimento da linguagem vai além de apenas saber o significado das palavras — aqui entram em cena a semântica e a similaridade semântica. A semântica tradicional lida com os significados das palavras ou frases isoladamente, mas o Rufus utiliza a similaridade semântica para entender como as frases se relacionam entre si, capturando o contexto mais profundo do que os usuários realmente querem dizer ao fazer perguntas.
Essa capacidade permite que o Rufus conecte as perguntas dos clientes de maneira mais precisa às sugestões de produtos certas, compreendendo não apenas as palavras, mas também as intenções por trás delas. Mais adiante, exploraremos a otimização de inferências, que expande essas ideias para ajudar o Rufus a tirar conclusões inteligentes a partir das informações que processa.
Por que isso é importante?
Essa abordagem muda completamente a forma como os compradores encontram o que precisam. Para os clientes, significa resultados mais rápidos e inteligentes, que eliminam informações irrelevantes e proporcionam uma experiência de compra mais eficiente.
Explorando o RUFUS Blueprint: O que Podemos Aprender ao Entender o Rufus
A Figura 1 oferece uma visão de como as frases nominais desempenham um papel crucial ao conectar as consultas dos usuários a recomendações de produtos relevantes. O sistema vai além da correspondência básica de palavras-chave, concentrando-se na intenção por trás das perguntas dos usuários, extraindo frases nominais-chave tanto da consulta quanto da resposta para orientar suas recomendações.
Por exemplo, na pergunta:
“Como remover unhas de gel?”
O sistema gera a resposta:
“A remoção de unhas de gel envolve mergulhá-las em acetona pura.”
Dessa interação, ele identifica frases como “unhas de gel” e “acetona pura” como elementos-chave. Essas frases nominais servem como base para entender o que o usuário precisa e encontrar os produtos certos.
Indo Além das Palavras – Compreendendo o Significado
O que diferencia esse sistema é sua capacidade de entender as relações entre essas frases. Em vez de simplesmente buscar produtos rotulados como “unhas de gel” ou “acetona pura,” ele utiliza um modelo de similaridade semântica treinado para reconhecer o contexto.
Isso permite que ele entenda que “acetona pura” está intrinsecamente ligada à “remoção de unhas de gel,” mesmo que as palavras exatas não coincidam.
Essa compreensão semântica possibilita uma busca por produtos muito mais inteligente. Por exemplo, o sistema pode recomendar várias marcas de acetona ou removedores de esmalte com base na relação que reconhece entre a consulta do usuário e os produtos relevantes.
Classificação Inteligente para Melhores Recomendações
O sistema não se limita a identificar produtos relevantes; ele os classifica de forma inteligente para priorizar as opções mais úteis para o usuário. Essa classificação é baseada em:
- Relevância Semântica: Frases que se alinham mais estreitamente com a intenção do usuário, conforme determinado por suas pontuações de similaridade semântica, recebem classificações mais altas.
- Feedback do Usuário: Com o tempo, o sistema aprende com os cliques dos usuários, refinando suas classificações para refletir melhor o que os compradores consideram útil.
Isso significa que otimizar suas páginas para alinhar-se semanticamente — em vez de confiar apenas em uma correspondência direta, palavra por palavra — é essencial para que o Rufus escolha seu produto como um resultado de busca. Ao garantir que seu produto seja uma correspondência semântica para uma pergunta que o usuário possa fazer, você aumenta as chances de o Rufus fornecer a resposta e sugerir seu produto como parte de suas recomendações.
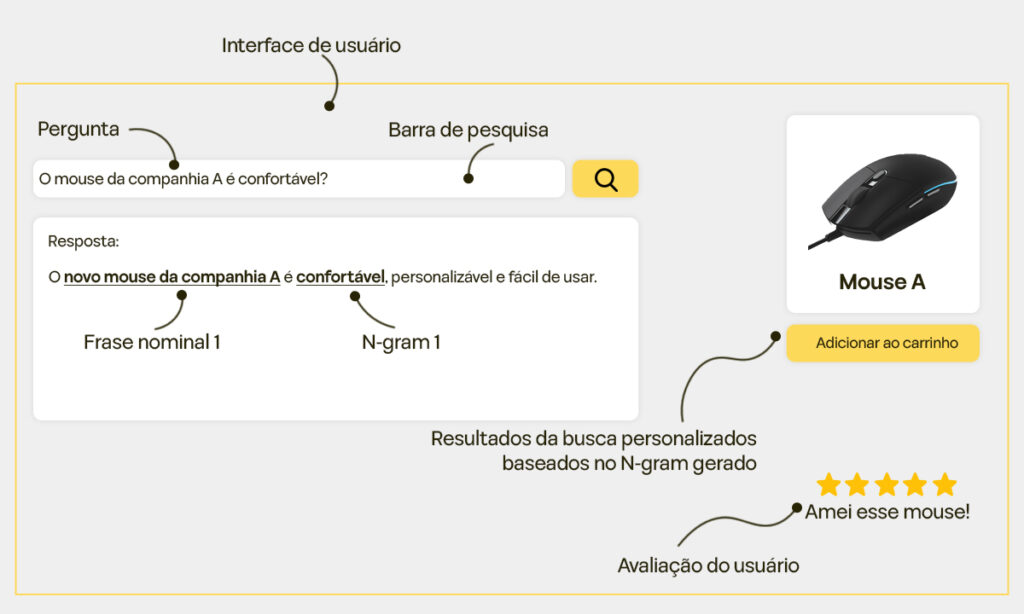
A Figura 2 apresenta um exemplo simples, mas poderoso, de como o Rufus transforma uma pergunta do usuário em uma recomendação de produto relevante. Imagine um comprador perguntando:
Ele está procurando informações sobre o nível de conforto de um modelo específico de mouse.
O Rufus analisa a consulta e responde com:
“O mouse mais recente da empresa A é confortável, personalizável e fácil de usar.”
Mas ele não para por aí. A partir dessa resposta, ele identifica “mouse confortável” como uma frase nominal-chave, capturando a intenção da pergunta do usuário. Com essas informações, o sistema pesquisa em seu banco de dados de produtos e recomenda a opção mais relevante — provavelmente o mouse mais recente da empresa A. Uma representação visual do produto também é exibida, tornando a sugestão mais envolvente e útil.
Centralidade das Frases Nominais no Entendimento do Rufus
Conforme detalhado nas seções 0015 e 0016 da patente, as frases nominais são centrais para como o Rufus entende e processa as consultas dos usuários. Em vez de apenas corresponder palavras, o sistema se concentra no significado por trás da pergunta e da resposta gerada.
Por exemplo, “mouse confortável” encapsula o que o usuário realmente está pedindo, preenchendo a lacuna entre uma consulta simples e uma recomendação acionável. Essa abordagem oferece uma experiência de busca mais rica e relevante, aprimorando a jornada de compra dos usuários.
Classificação e Pontuação de Frases Nominais
Para tornar o processo ainda mais preciso, o Rufus classifica e pontua essas frases nominais. Ele avalia sua relevância utilizando fatores como similaridade semântica e comportamento do usuário, incluindo os produtos que os usuários costumam clicar. Isso garante que as correspondências mais significativas e precisas sejam priorizadas nas recomendações.
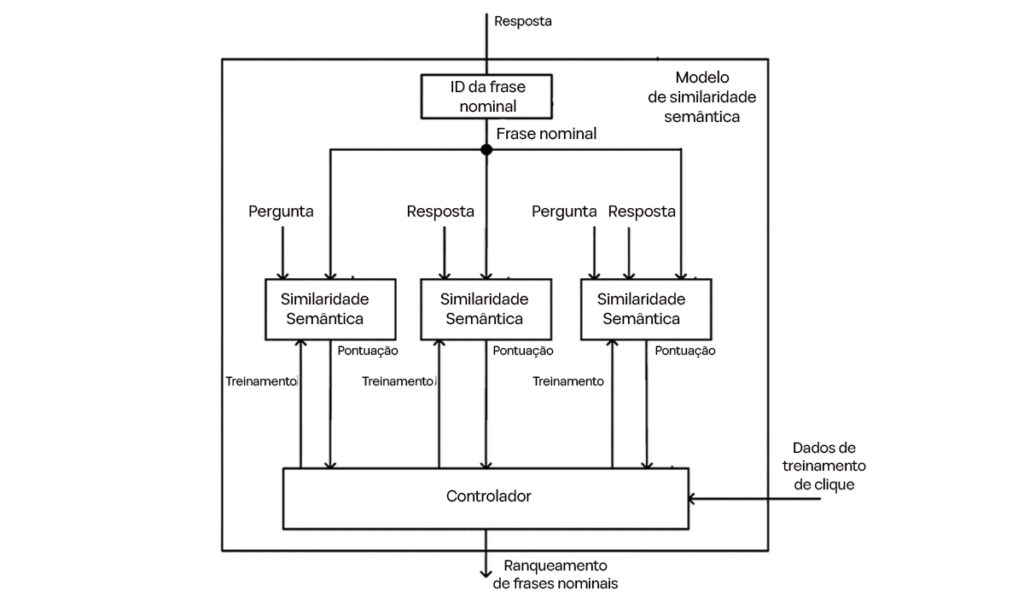
A Figura 3 fornece uma visão mais detalhada de como o sistema lida com perguntas geradas pelos usuários e pelo sistema para refinar as recomendações de produtos. Essa abordagem de dupla consulta não apenas garante sugestões relevantes, mas também aprende continuamente com o comportamento dos usuários para melhorar ao longo do tempo.
Perguntas Geradas pelo Usuário
As perguntas geradas pelos usuários são o núcleo do sistema. Essas perguntas, inseridas diretamente na interface do usuário, refletem as necessidades específicas dos compradores — como:
“Quais são os melhores tênis para pés planos?”
O sistema processa imediatamente essas perguntas para extrair frases nominais-chave. Por exemplo, na pergunta acima, frases como “tênis” e “pés planos” seriam identificadas. Essa análise é essencial para entender a intenção do usuário e restringir as categorias de produtos relevantes.
Perguntas Geradas pelo Sistema
Além da entrada do usuário, o sistema também gera suas próprias perguntas. Essas perguntas não são aleatórias, mas baseadas em padrões detectados pelo sistema ao analisar interações dos usuários, particularmente utilizando os Dados de Treinamento de Cliques.
Dados de Treinamento de Cliques – Um Fator Crucial
Os Dados de Treinamento de Cliques registram o que os compradores fazem após fazer uma pergunta, especificamente quais produtos eles clicam. Por exemplo, se os usuários frequentemente clicam em produtos que enfatizam “amortecimento” após perguntar sobre tênis para pés planos, o sistema aprende que o amortecimento é uma preferência essencial para esse tipo de consulta.
Com esse insight, o sistema pode gerar internamente uma pergunta complementar como:
“Quais tênis oferecem o máximo de amortecimento?”
Essas perguntas geradas pelo sistema ajudam a refinar a compreensão das necessidades do usuário e a melhorar a precisão das recomendações.
Impacto dos Dados de Treinamento de Cliques:
Fornece feedback ao rastrear interações dos usuários com as recomendações de produtos.
Permite que o sistema aprenda com o comportamento, identificando tendências que informam melhores sugestões.
Garante que o sistema evolua ao longo do tempo, tornando-se mais inteligente e responsivo com cada interação.
A Figura 3 demonstra como o sistema usa uma combinação de perguntas geradas pelo usuário e pelo sistema para melhorar as recomendações de produtos. Ao aproveitar insights dos Dados de Treinamento de Cliques, o Rufus vai além de simplesmente responder perguntas, aprendendo, refinando e personalizando a experiência de compra para garantir que os usuários encontrem exatamente o que procuram.
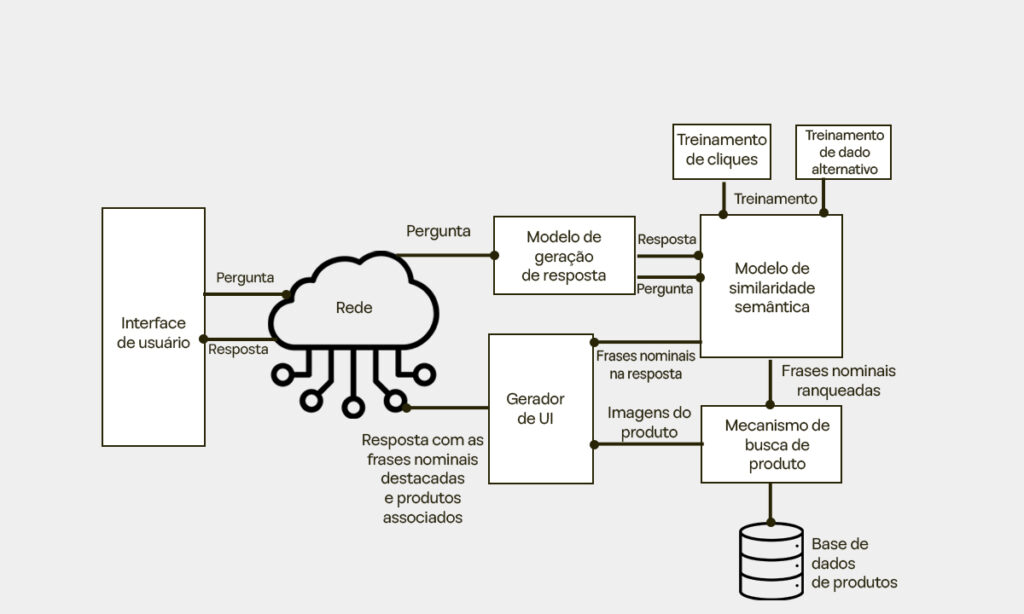
Expandindo o Modelo de Similaridade Semântica introduzido na Figura 3, a Figura 4 oferece uma visão detalhada de como o sistema avalia e classifica frases nominais para refinar suas recomendações.
O sistema usa o Modelo de Similaridade Semântica para analisar as frases nominais extraídas tanto da consulta do usuário quanto da resposta gerada. Cada frase recebe uma pontuação de relevância baseada em sua conexão semântica com a pergunta do usuário.
Por exemplo:
Na consulta sobre “tênis para pés planos,” frases como “suporte para arco” podem receber uma pontuação mais alta do que termos gerais como “tênis”, pois refletem melhor a intenção do usuário.
Esse modelo é continuamente treinado usando dados como Frases de Treinamento de Frases Nominais e Dados de Treinamento de Cliques. Isso permite que o modelo reconheça relações sutis entre palavras e frases, garantindo que ele avalie como elas se alinham às necessidades do usuário.
Após calcular as pontuações, o sistema classifica as frases nominais em ordem de relevância. Essa classificação garante que as frases mais significativas — aquelas que capturam verdadeiramente a intenção do usuário — sejam priorizadas durante as buscas por produtos.
O sistema evolui com feedback de usuários, ajustando continuamente seus processos de pontuação e classificação para refletir as preferências reais ao longo do tempo.
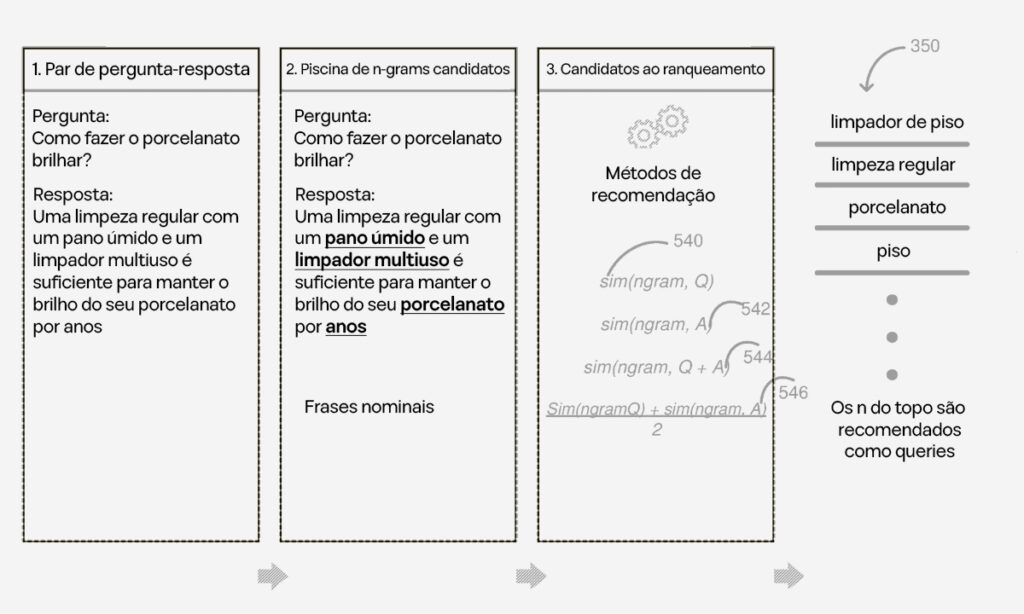
A Figura 5 detalha como o sistema processa um Par de Pergunta e Resposta para extrair, classificar e priorizar frases nominais, orientando o processo de recomendação de produtos.
Exemplo:
Pergunta (Q): “Como fazer o porcelanato brilhar?”
Resposta (R): “Uma limpeza regular com um pano úmido e um limpador multiuso é suficiente para manter o brilho do seu porcelanato por anos.”
A partir dessa interação, o sistema identifica um conjunto de frases nominais candidatas, como:
- “Limpeza regular com pano úmido”
- “Limpador multiuso”
- “Porcelanato”
- “Anos”
Cada frase recebe uma pontuação de similaridade semântica com base em sua relevância para a consulta original. Por exemplo:
“Porcelanato” pode receber uma pontuação alta por estar diretamente relacionada à intenção da pergunta.
Um termo genérico como “Anos” pode receber uma pontuação mais baixa devido à sua relevância limitada.
A Figura 5 ilustra como o sistema aproveita pares de Perguntas e Respostas para oferecer recomendações altamente relevantes, aprimorando continuamente suas sugestões com base em dados de treinamento e feedback dos usuários.
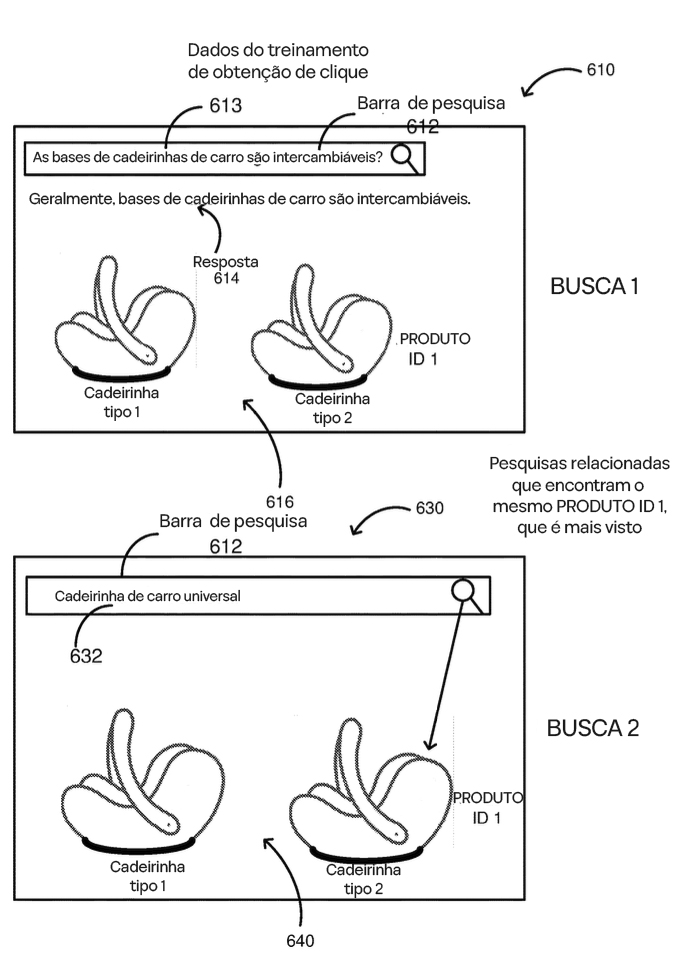
Conforme discutido anteriormente, a Figura 6 revela como o sistema vai além de perguntas explícitas, aprendendo também com termos de busca padrão para refinar suas recomendações inteligentes. Isso amplia ainda mais as capacidades do sistema, garantindo que ele atenda às necessidades dos usuários de forma abrangente e precisa.
Entendendo a Entrada do Usuário: Perguntas vs. Termos de Busca
O processo começa com a entrada do usuário, que pode ser uma pergunta direta, como:
“As bases de cadeirinhas de carro são intercambiáveis?”
ou um termo de busca padrão, como:
“cadeirinha de bebê.”
Enquanto as perguntas exploram compatibilidade ou características, os termos padrão são mais diretos e focados em produtos. Independentemente do tipo de entrada, o sistema responde gerando uma resposta e exibindo imagens de produtos relacionados, como Tipo de Assento 1 e Tipo de Assento 2, ambos vinculados ao ID do Produto 1.
Uma parte essencial dessa resposta é o destaque de frases nominais na resposta, como “cadeirinha de bebê universal”. Essas frases guiam o usuário para buscas mais específicas. Por exemplo, após visualizar a frase destacada, o usuário pode refinar sua consulta digitando “cadeirinha de bebê universal”. O sistema então responde novamente, exibindo os mesmos produtos associados ao ID do Produto 1, reforçando a conexão entre a consulta inicial e a busca refinada.
Essa interação gera valiosos dados de treinamento de cliques. Ao rastrear que o mesmo produto apareceu nas buscas inicial e refinada, o sistema aprende quais frases destacadas foram relevantes e como os usuários navegam de consultas amplas para escolhas de produtos específicas. Com o tempo, isso ajuda o sistema a associar consultas aparentemente diferentes ao mesmo produto, aprimorando sua capacidade de recomendar itens relevantes em buscas futuras.
A Figura 6 demonstra como o sistema vai além da correspondência padrão de palavras-chave para aprender com uma ampla variedade de entradas dos usuários. Frases nominais destacadas atuam como uma ponte entre consultas amplas e categorias específicas de produtos, ajudando os usuários a refinar suas buscas enquanto fornecem ao sistema dados para melhorar as recomendações.
Dica: Antecipe as perguntas que os usuários podem fazer sobre o seu produto — como uso, benefícios ou compatibilidade — e incorpore respostas naturais em sua descrição.
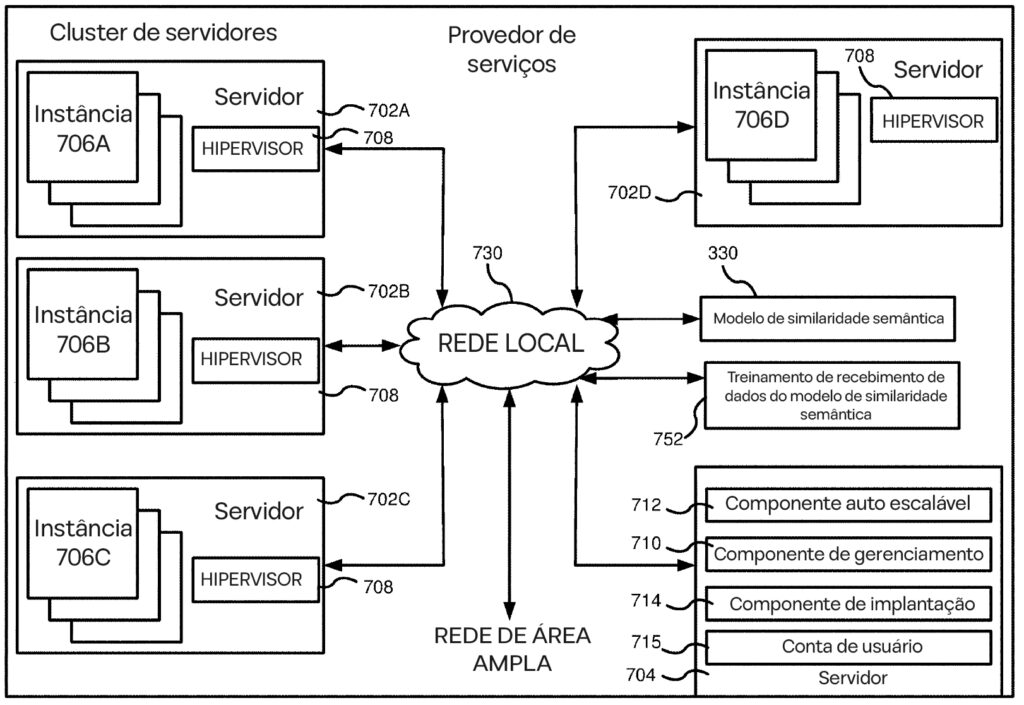
A Figura 7 apresenta a arquitetura de um sistema baseado em nuvem, destacando como seus componentes trabalham juntos para gerenciar recursos, adaptar-se às demandas dos usuários e oferecer serviços contínuos.
No núcleo está um cluster de servidores (706), interconectados por uma Rede Local (LAN 702) e gerenciados pelo Provedor de Serviços de Computação (700). Esses servidores são responsáveis por:
- Modelo de Similaridade Semântica (750): Processa consultas de usuários ao entender relações semânticas entre frases.
- Aquisição de Dados de Treinamento (752): Coleta dados de usuários para refinar a precisão do modelo.
- Autoescalonamento (712): Ajusta dinamicamente os recursos para lidar com variações de carga.
- Implantação (714): Gerencia atualizações de software e lançamento de novos recursos.
O sistema se conecta aos usuários por meio de uma Rede de Área Ampla (WAN 740), enquanto componentes como Gerenciamento de Contas de Usuário (716) e Componente de Gerenciamento (710) lidam com interações e segurança.
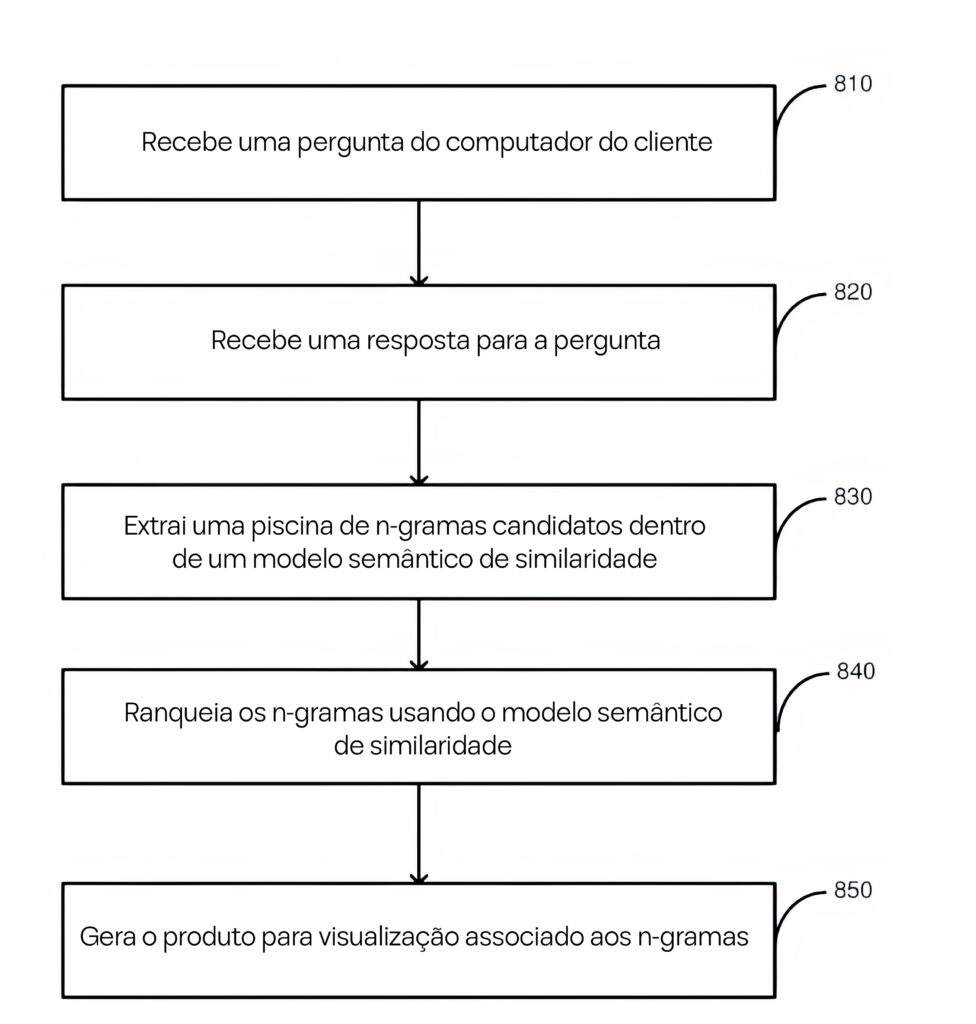
A Figura 8 descreve o processo passo a passo que o sistema usa para transformar uma pergunta do usuário em uma recomendação de produto relevante.
O Processo:
Recebimento da Pergunta (810):
O sistema começa aceitando uma pergunta do usuário, como:
“Como remover unhas de gel?”
Recuperação da Resposta (820):
O sistema gera uma resposta com base em um banco de dados existente ou em um módulo de perguntas e respostas, como:
“A remoção de unhas de gel envolve mergulhá-las em acetona pura.”
Extração de N-Gramas (830):
Da resposta, o sistema identifica n-gramas (frases nominais) como “unhas de gel” e “acetona pura”. Essas frases são analisadas por um Modelo de Similaridade Semântica.
Classificação dos N-Gramas (840):
O modelo avalia e classifica os n-gramas com base em:
- Frequência: Quantas vezes a frase aparece na resposta.
- Relevância: Quão bem ela se alinha com a pergunta.
- Dados de Cliques de Usuários: Insights sobre frases que levam a cliques em produtos.
Seleção e Exibição do Produto (850):
Baseando-se na classificação dos n-gramas, o sistema busca produtos alinhados semanticamente com as frases mais relevantes, como “acetona pura”.
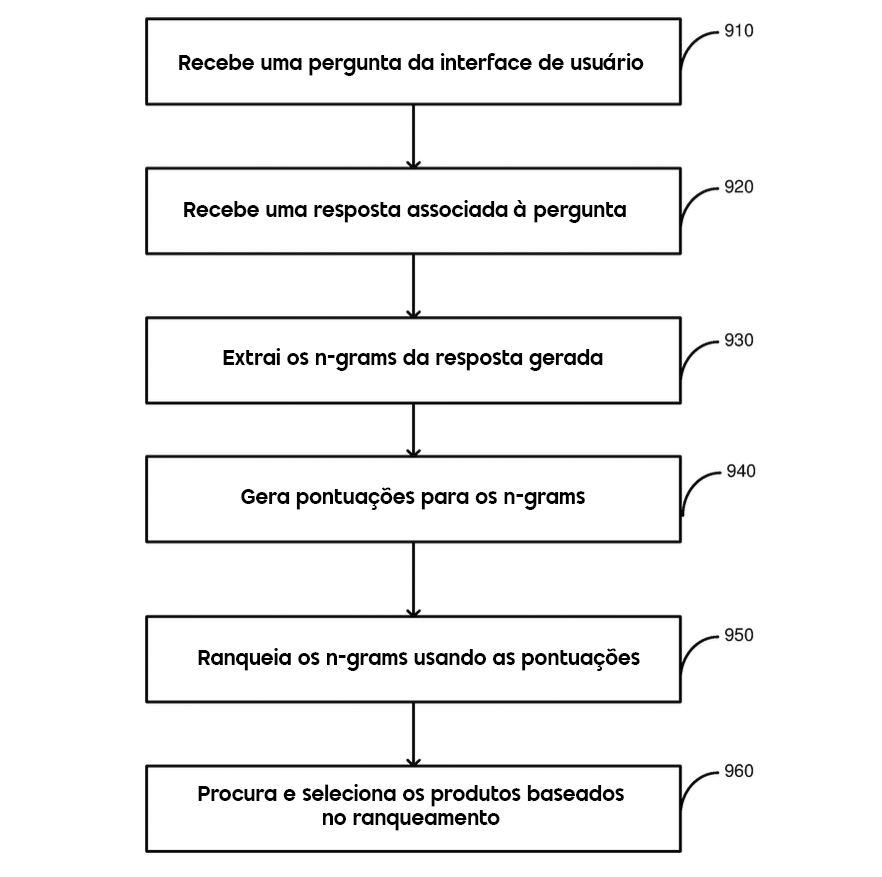
A Figura 9 destaca um processo mais integrado, onde n-gramas são extraídos diretamente da resposta gerada para uma pergunta, orientando as recomendações de produtos.
Diferença Principal:
Na Figura 8, a geração da resposta e a extração dos n-gramas são etapas separadas. Já na Figura 9, essas fases estão integradas, criando um caminho mais direto entre a entrada do usuário e as recomendações.
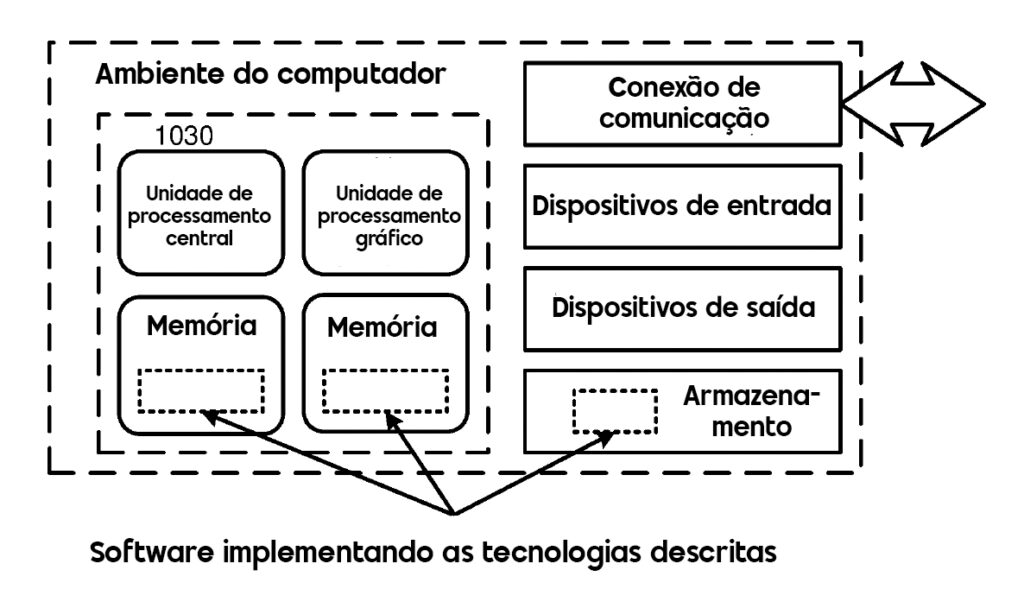
A Figura 10 detalha os componentes de hardware e software que possibilitam o sistema, como:
- CPU: Processamento central.
- Memória e Armazenamento: Gerenciamento de dados.
- Dispositivos de Entrada/Saída: Interação com o usuário.
- Conexões de Comunicação: Acesso externo.
O software integra esses elementos para executar os processos descritos, mostrando flexibilidade em diferentes ambientes de computação.
Resumo Final
As reivindicações desta patente apresentam um poderoso framework que combina processamento de linguagem natural, análise semântica e comportamento do usuário para criar recomendações de produtos personalizadas. Com flexibilidade, adaptabilidade e foco no usuário, a invenção estabelece as bases para uma maneira mais inteligente e intuitiva de conectar usuários aos produtos de que precisam.
O Rufus da Amazon é uma IA conversacional transformadora que atua como um navegador e educador pessoal no marketplace da Amazon. Integrando dados proprietários, OCR, compreensão semântica e imagens, o Rufus oferece recomendações contextualmente ricas e visualmente envolventes. Adaptando-se dinamicamente à jornada do cliente, garante que os produtos não apenas sejam encontrados, mas também criem uma conexão emocional com os compradores, redefinindo o e-commerce por meio de uma otimização multimodal e multidimensional.
Tem dúvidas?
Se você está procurando orientação especializada adaptada aos objetivos exclusivos da sua marca, a EcomVision está aqui! Sinta-se à vontade para se conectar comigo no LinkedIn ou entrar em contato com qualquer dúvida. E se você estiver pronto para levar sua estratégia da Amazon para o próximo nível, entre em contato conosco ou Agende uma avaliação sem compromisso para ver como podemos apoiar seu crescimento!

